
Cloud Monitoring Tools
Gain complete cloud resource oversight and control. Our Cloud Monitoring Tools offer comprehensive visibility for optimized performance and heightened security across your cloud AWS and Azure infrastructure.
Video
WhatsUp Gold’s Cloud Monitoring Software Overview
Comprehensive Cross-Technology Cloud Monitoring Tool
WhatsUp Gold treats the cloud just like the rest of your network and displays that information in context with the rest of your network infrastructure. Monitor, report and alert on the status of every single metric available via the AWS and Azure APIs. You can then integrate that information into your alert center, dashboards and your interactive network map so you can quickly drill-down to issues and isolate the cause of problems that span technology silos.
Discover every element of your AWS or Azure cloud environment and view it on your network map
Apply WhatsUp Gold’s cloud monitoring tool to every single parameter supported by the AWS and Azure cloud APIs
3 of 4 level 1, heading level 1
Identify cloud vs. on-premise network issues fast and eliminate finger-pointing
Monitor and report on cloud billing to prevent expensive surprises
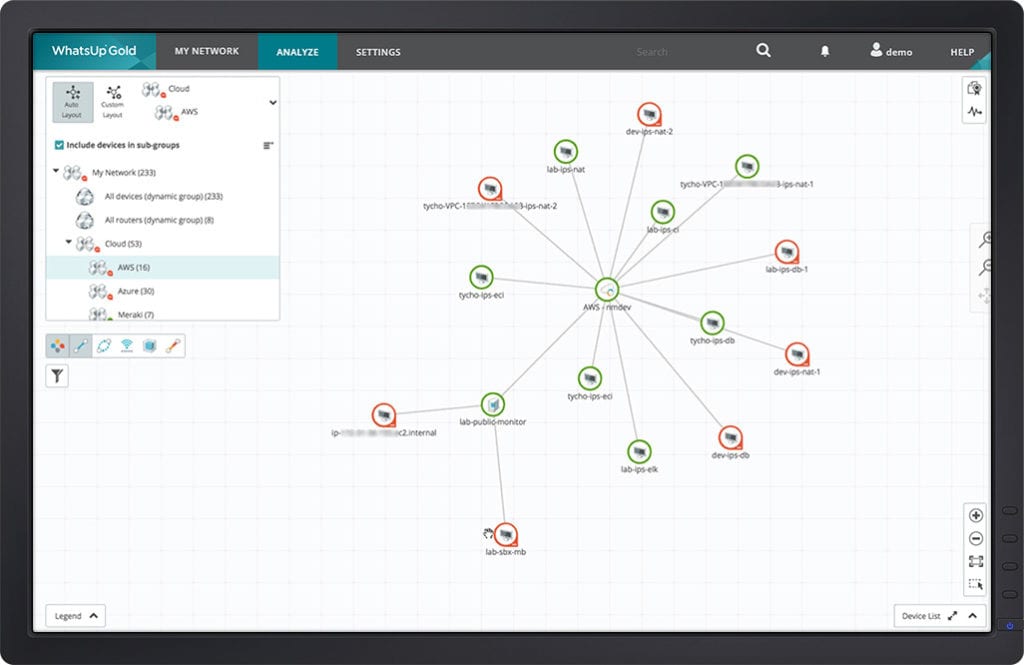
Map Cloud Resources
WhatsUp Gold Cloud Monitoring Software will automatically discover cloud-based resources and display them on the same interactive map that shows your on-premises network. Not only can you now view and modify them like any other device, you get end-to-end visibility of your entire networked infrastructure for faster troubleshooting.
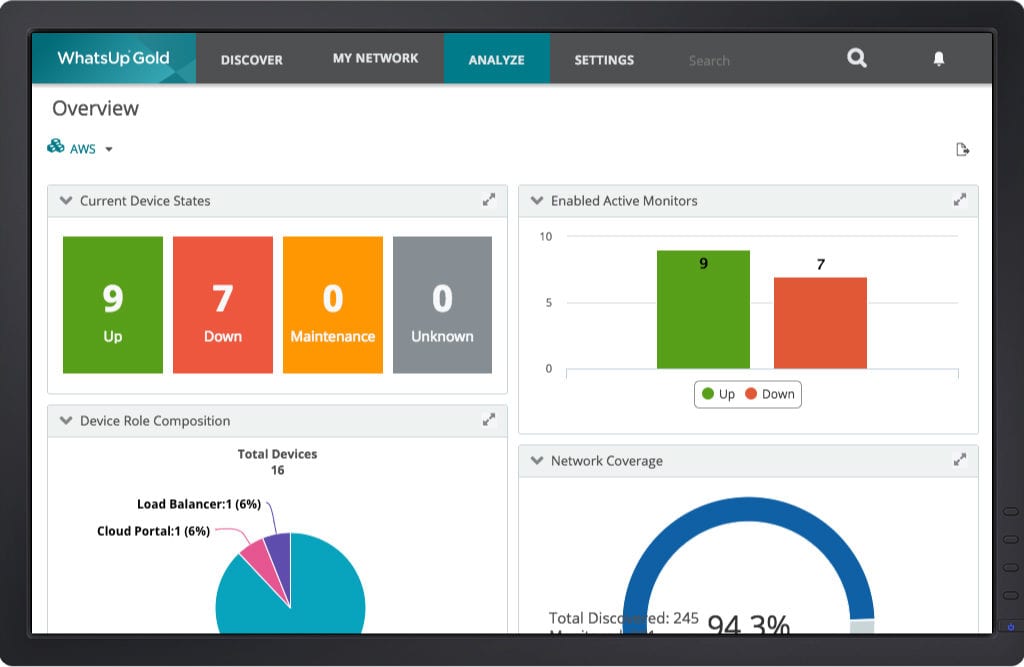
Monitor Usages and Costs
Every parameter accessible through the Amazon AWS or Microsoft Azure cloud APIs can be monitored by WhatsUp Gold's cloud monitoring solution. Problems are highlighted right on the map for at-a-glance troubleshooting. Drill down with a single click to view performance and availability details for any cloud-based resource. Do you have unused or under-used cloud resources that you’re still paying for? Understanding what you’re using and when makes it easy to optimize your cloud resources and lower your costs. Tracking trends for longer than the standard 30 days makes optimization even easier.
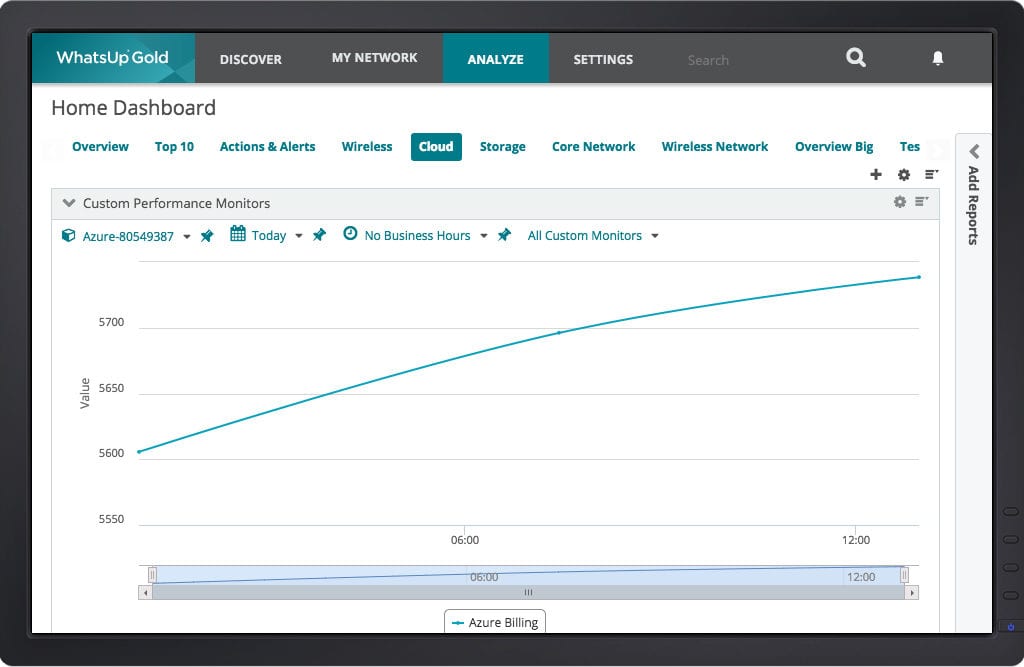
Get Proactive Alerts
Track and alert on cloud usage and billing so there are no surprises in the next invoice. Proactively alert on performance issues impacting key services. Set your own threshold-based alerts on key performance and availability metrics and get notified via Email, SMS, Slack or log files.
Monitor End-User Experience
Organizations need to know what users experience when using their cloud-based applications. WhatsUp Gold monitors metrics like response times and frequency of use to get a complete performance picture.
Maintain Instant Visibility
WhatsUp Gold Cloud Monitoring Software supports customizable dashboards that provide instant visibility into what’s up, what’s down, what’s seeing heavy usage, what’s idle, etc.
Create Custom Dashboards
Create a single dashboard view of your wired and wireless network, physical, virtual and cloud-based servers to quickly assess the health of your entire IT infrastructure and to identify and fix problems before they impact users, applications or the business.
Know What Your Cloud Provider Knows
Most organizations aren’t tracking their cloud resources, how they’re using them or how much they’re spending – they just pay the monthly bill from the cloud service provider. Unless that bill significantly increases, they have no incentive to determine if they’re really using all those resources or if they’re being accurately billed. By implementing cloud monitoring you can identify under-used cloud services and identify money-saving optimization opportunities.
of businesses see significant seasonal variation of network usage throughout the year.
Monitor Azure Cloud Services
The Azure Cloud Monitoring Portal has a ton of information, but it’s not looking at the rest of your network. Monitoring Azure via the Azure API lets you integrate cloud resource details into your network monitoring.
Monitor AzureMonitor Amazon Web Services (AWS)
AWS monitoring leverages AWS APIs to give you access to the details of what your cloud resources are doing. You can set up alerts or reports on specific details that Amazon Cloudwatch may not bother to highlight.
Monitor AWSFrequently Asked Questions
Why use WhatsUp Gold to monitor the cloud?
Cloud Service Providers can't provide the 'in-context visibility' you need across your end-to-end network to identify problems before end-users do and resolve them quickly.
Will that make troubleshooting easier?
Research shows that IT shops that rely on integrated, rather than single-silo, tools troubleshoot problems faster and have fewer problems first reported by end-users.
How will using one tool improve visualization?
WhatsUp Gold automatically generates an interactive map that shows the status of and connectivity between cloud-based resources.
What metrics will WhatsUp Gold monitor?
WhatsUp Gold will access and monitor any statistic available through either the Amazon AWS or Microsoft Azure API.
How up to date are the monitored metrics?
While monitoring is automatically set to poll every minute, admins can customize their polling cycles to meet their specific needs.
What kind of notifications can I receive?
You can configure notifications for delivery via email, SMS or Slack. We even integrate with IFTTT.
WhatsUp Gold Licensing
Flexible licensing options to suit your organization's needs.
Delivers real-time visibility into device health, application performance, and traffic flows so IT teams can ensure uptime, optimize capacity and help prevent service disruptions. Helps reduce operational costs, accelerate troubleshooting and maintain a consistent user experience.
Business
starting from
Enterprise
starting from
Enterprise Plus
starting from
Premium
starting from
Total Plus
starting from
Get Started
Complete the form to download your free trial of WhatsUp Gold.
Learn more about cloud monitoring.
What is cloud monitoring?
Cloud monitoring is the process of reviewing and managing the operational workflow and processes within a cloud infrastructure or asset. It’s generally implemented through automated monitoring software that gives central access and control over the cloud infrastructure. Admins can review operational status and health of cloud devices and components.